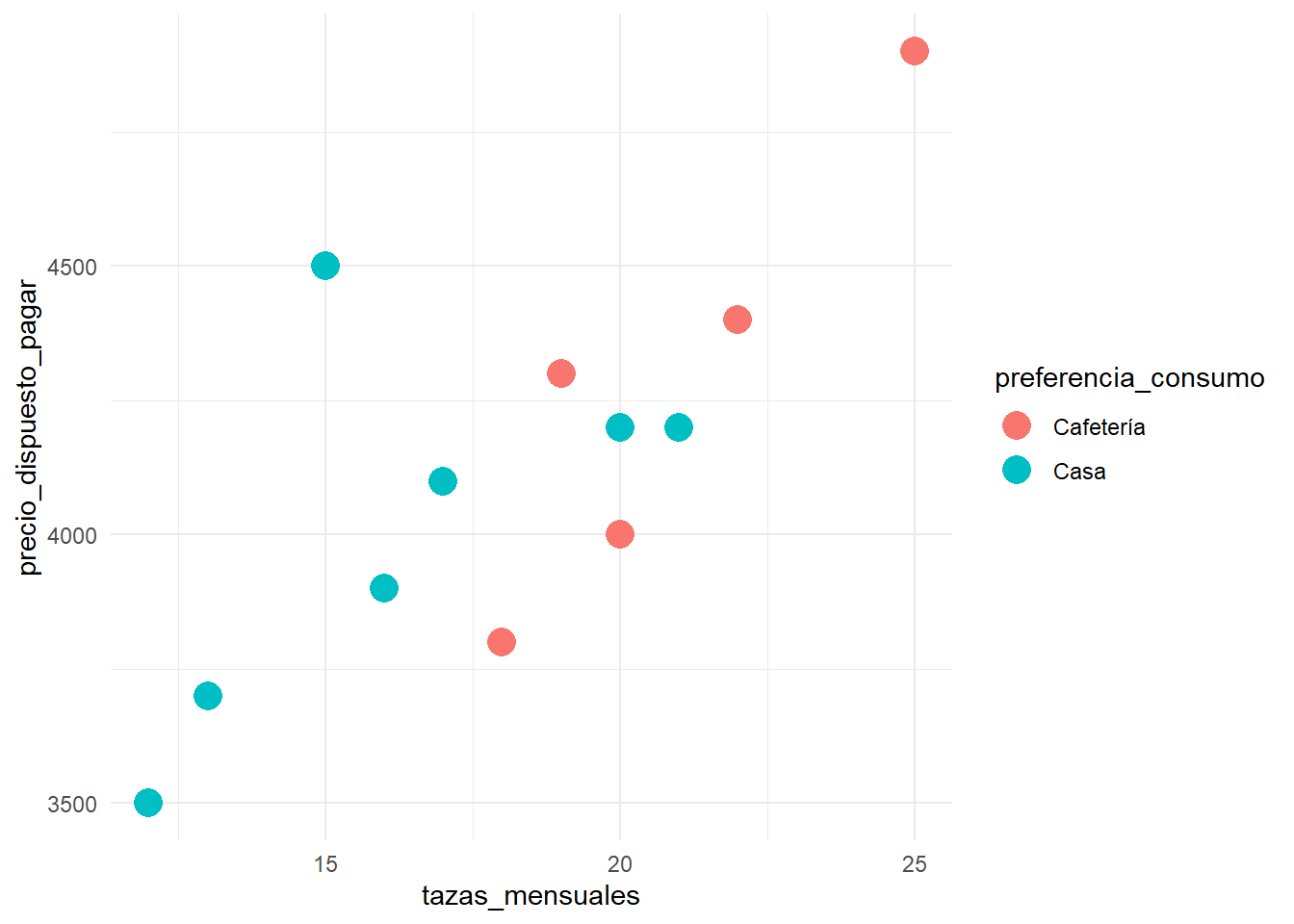
# Simulaciónmodelo_inicial <-lm(precio_dispuesto_pagar ~ tazas_mensuales , data = datos_)nueva_muestra <-data.frame(tazas_mensuales =rnorm(200, mean =mean(datos_$tazas_mensuales), sd =sd(datos_$tazas_mensuales)))# Usamos el modelo inicial para predecir 'precio_dispuesto_pagar' en la nueva muestranueva_muestra$precio_dispuesto_pagar <-predict(modelo_inicial, nueva_muestra) +rnorm(200, 0, 500) # Añadimos ruidoggplot(nueva_muestra,aes(x=tazas_mensuales,y=precio_dispuesto_pagar))+geom_point(size=5)+theme_minimal()
Code
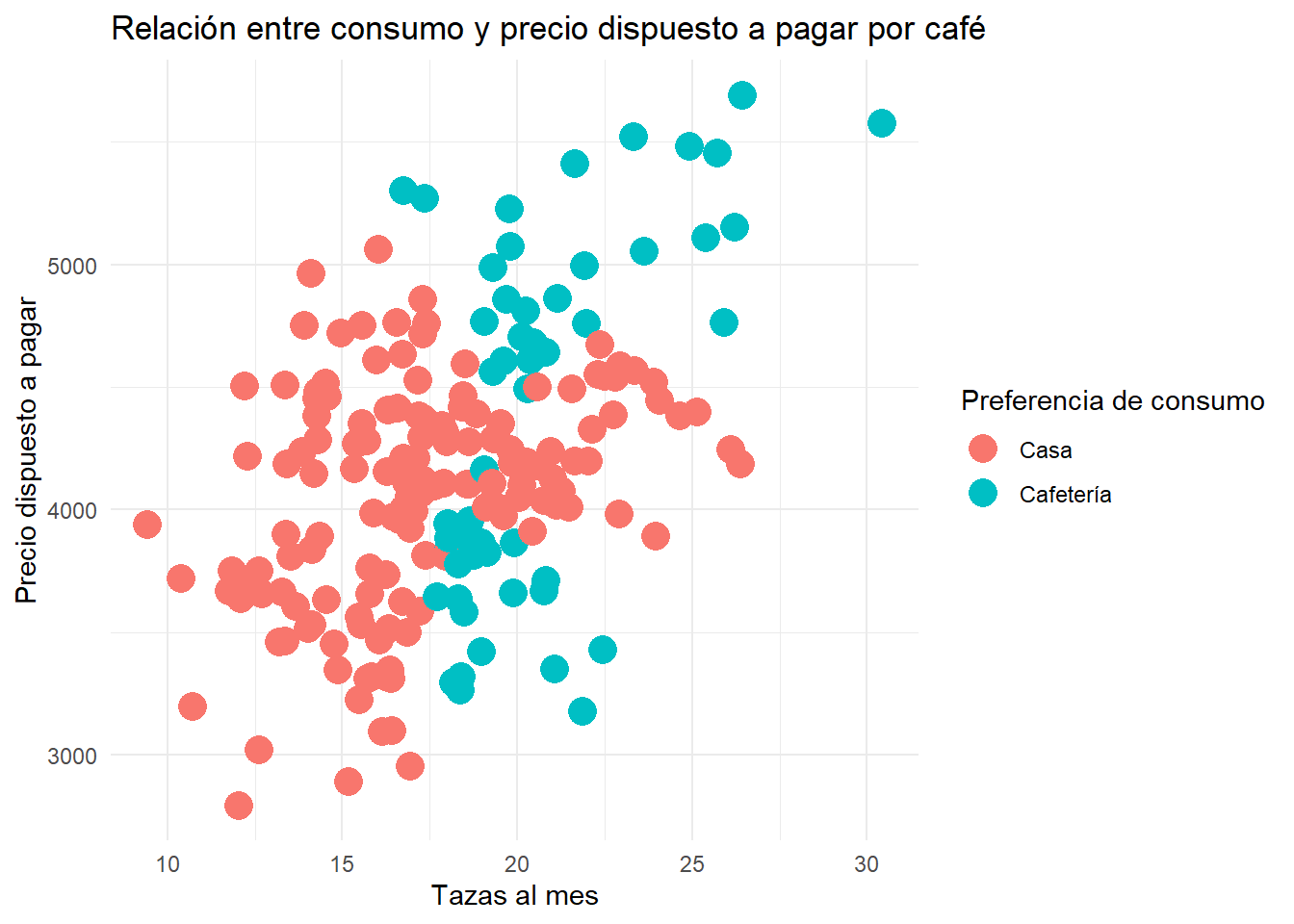
# Aplicar el modelo KNN para predecir la preferencia de consumo# Escalamos las variables para asegurar que están en la misma escalaescala_datos <-scale(datos_[, c("precio_dispuesto_pagar", "tazas_mensuales")])escala_nueva_muestra <-scale(nueva_muestra[, c("precio_dispuesto_pagar", "tazas_mensuales")])# Predicción de la preferencia de consumo con KNNnueva_muestra$preferencia_consumo <-knn(train = escala_datos,test = escala_nueva_muestra,cl = datos_$preferencia_consumo,k =3# Número de vecinos)nueva_muestra$preferencia_consumo <-factor(nueva_muestra$preferencia_consumo, levels =c("Casa", "Cafetería"))ggplot(nueva_muestra,aes(x=tazas_mensuales,y=precio_dispuesto_pagar,color=preferencia_consumo))+geom_point(size=5)+theme_minimal()+labs(title ="Relación entre consumo y precio dispuesto a pagar por café",x ="Tazas al mes",y ="Precio dispuesto a pagar",color ="Preferencia de consumo")
Code
# Dividir datos en conjunto de entrenamiento y prueba (80/20)trainIndex <-createDataPartition(nueva_muestra$precio_dispuesto_pagar, p = .8, list =FALSE, times =1)datos_entrenamiento <- nueva_muestra[trainIndex, ]datos_prueba <- nueva_muestra[-trainIndex, ]# Entrenar el modelo de regresión linealmodelo <-train( precio_dispuesto_pagar ~ tazas_mensuales + preferencia_consumo,data = datos_entrenamiento,method ="lm")# Resumen del modelosummary(modelo)
Call:
lm(formula = .outcome ~ ., data = dat)
Residuals:
Min 1Q Median 3Q Max
-1275.73 -317.66 12.66 300.86 1189.06
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2919.07 224.12 13.024 < 2e-16 ***
tazas_mensuales 65.89 12.77 5.162 7.3e-07 ***
preferencia_consumoCafetería 90.59 99.97 0.906 0.366
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 497.8 on 157 degrees of freedom
Multiple R-squared: 0.1947, Adjusted R-squared: 0.1845
F-statistic: 18.98 on 2 and 157 DF, p-value: 4.143e-08
Code
# Realizar predicción en el conjunto de pruebapredicciones <-predict(modelo, datos_prueba)# Visualizar relación de tazas_mensuales y precio_dispuesto_pagar con preferencia_consumog1<-ggplot(datos_prueba, aes(x = tazas_mensuales, y = precio_dispuesto_pagar)) +geom_point(aes(color=preferencia_consumo),size=3) +geom_smooth(method ="lm") +labs(title ="Relación entre Consumo y Precio Dispuesto a Pagar por Café",x ="Tazas al Mes",y ="Precio Dispuesto a Pagar",color ="Preferencia de Consumo") +theme_minimal()plotly::ggplotly(g1)
Code
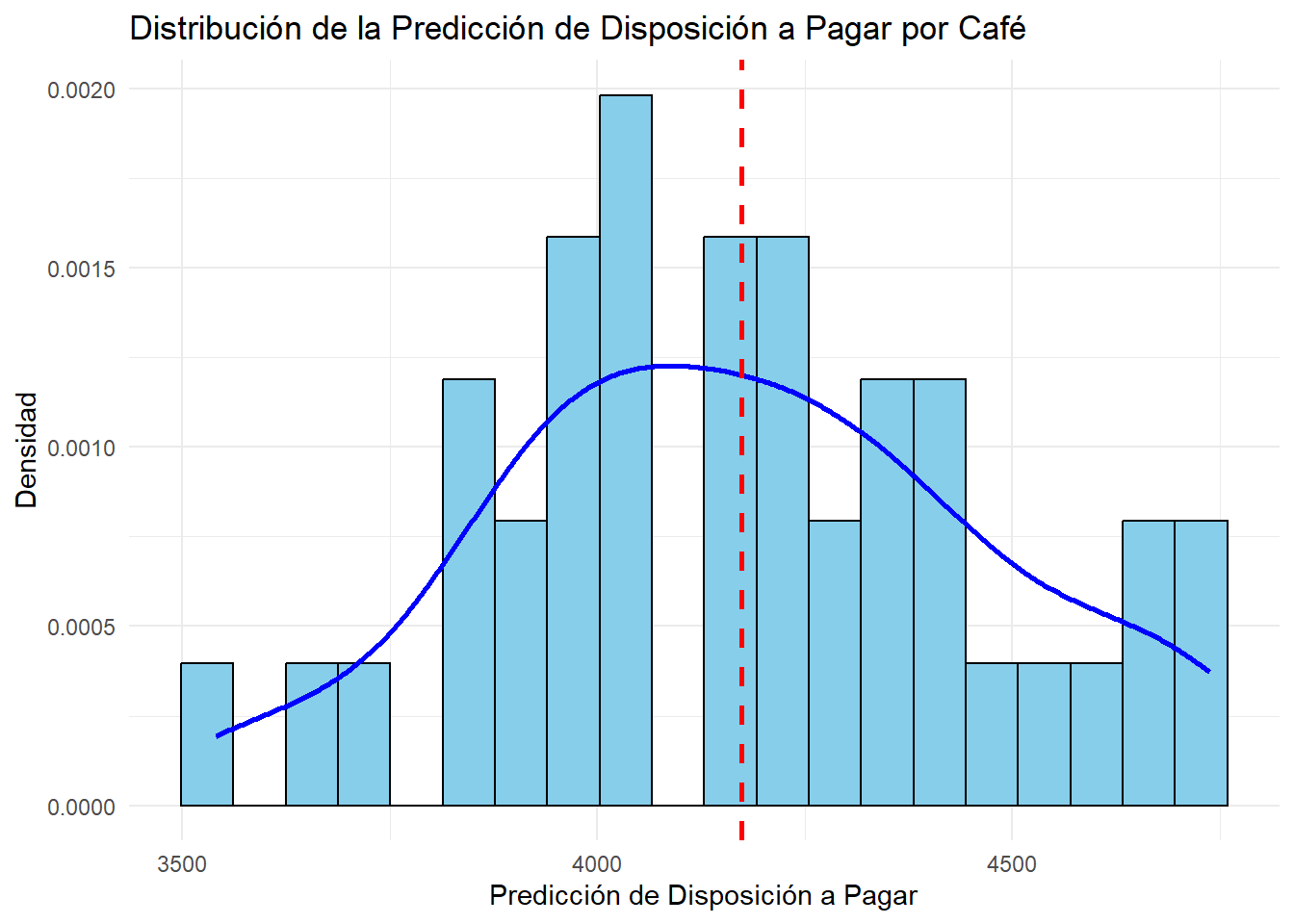
# Distribución de las prediccionesggplot(data.frame(predicciones), aes(x = predicciones)) +geom_histogram(aes(y = ..density..), bins =20, fill ="skyblue", color ="black") +geom_density(color ="blue", size =1) +geom_vline(aes(xintercept =mean(predicciones)), color ="red", linetype ="dashed", size =1) +labs(title ="Distribución de la Predicción de Disposición a Pagar por Café",x ="Predicción de Disposición a Pagar",y ="Densidad") +theme_minimal()
Code
summary(predicciones)
Min. 1st Qu. Median Mean 3rd Qu. Max.
3540 3985 4166 4174 4367 4738
Code
shapiro.test(residuals(modelo))
Shapiro-Wilk normality test
data: residuals(modelo)
W = 0.99439, p-value = 0.8006
Code
library(lmtest)bptest(modelo$finalModel)
studentized Breusch-Pagan test
data: modelo$finalModel
BP = 17.884, df = 2, p-value = 0.0001308
Code
# Realizar una predicción para un nuevo datonuevo_dato <-data.frame(tazas_mensuales =20, preferencia_consumo ="Cafetería")prediccion_nuevo <-predict(modelo, nuevo_dato)cat("Predicción del precio dispuesto a pagar para el nuevo dato: ", prediccion_nuevo, "\n")
Predicción del precio dispuesto a pagar para el nuevo dato: 4327.542
Source Code
---title: "Modelo de Regresión Lineal"author: "Orlando Joaqui-Barandica"date: last-modifiedformat: html: toc: true number-sections: true code-fold: show df-print: paged code-tools: true theme: cosmoexecute: echo: true warning: false message: falsefreeze: autoeditor: visual---::: callout-note**Clase completa:** consulta/estudia la clase extendida aquí: ➡️ **[Ir a la clase completa (HTML)](https://juniorjb5.github.io/ClasesTD/2_Class_RegresionLineal/Class_2.html#1)**:::<!-- Opción B: embeber (ajusta la URL, ancho/alto) --><divstyle="border: 1px solid #ddd; border-radius: 8px; overflow: hidden;"><iframesrc="https://juniorjb5.github.io/ClasesTD/2_Class_RegresionLineal/Class_2.html#1" width="100%"height="520"style="border:0;"></iframe></div>## Simulación```{r}# Librerías necesariaslibrary(dplyr)library(ggplot2)library(caret)library(class)# Ejemplo de datos simulados con respuestas hipotéticasset.seed(123)datos_ <-data.frame(precio_dispuesto_pagar =c(4500, 3800, 4200, 3500, 4900, 4100, 3700, 4000, 4400, 3900, 4300, 4200),tazas_mensuales =c(15, 18, 20, 12, 25, 17, 13, 20, 22, 16, 19, 21),preferencia_consumo =as.factor(c("Casa", "Cafetería", "Casa", "Casa", "Cafetería", "Casa", "Casa", "Cafetería", "Cafetería", "Casa", "Cafetería", "Casa")))datos_ggplot(datos_,aes(x=tazas_mensuales,y=precio_dispuesto_pagar,color=preferencia_consumo))+geom_point(size=5)+theme_minimal()# Simulaciónmodelo_inicial <-lm(precio_dispuesto_pagar ~ tazas_mensuales , data = datos_)nueva_muestra <-data.frame(tazas_mensuales =rnorm(200, mean =mean(datos_$tazas_mensuales), sd =sd(datos_$tazas_mensuales)))# Usamos el modelo inicial para predecir 'precio_dispuesto_pagar' en la nueva muestranueva_muestra$precio_dispuesto_pagar <-predict(modelo_inicial, nueva_muestra) +rnorm(200, 0, 500) # Añadimos ruidoggplot(nueva_muestra,aes(x=tazas_mensuales,y=precio_dispuesto_pagar))+geom_point(size=5)+theme_minimal()# Aplicar el modelo KNN para predecir la preferencia de consumo# Escalamos las variables para asegurar que están en la misma escalaescala_datos <-scale(datos_[, c("precio_dispuesto_pagar", "tazas_mensuales")])escala_nueva_muestra <-scale(nueva_muestra[, c("precio_dispuesto_pagar", "tazas_mensuales")])# Predicción de la preferencia de consumo con KNNnueva_muestra$preferencia_consumo <-knn(train = escala_datos,test = escala_nueva_muestra,cl = datos_$preferencia_consumo,k =3# Número de vecinos)nueva_muestra$preferencia_consumo <-factor(nueva_muestra$preferencia_consumo, levels =c("Casa", "Cafetería"))ggplot(nueva_muestra,aes(x=tazas_mensuales,y=precio_dispuesto_pagar,color=preferencia_consumo))+geom_point(size=5)+theme_minimal()+labs(title ="Relación entre consumo y precio dispuesto a pagar por café",x ="Tazas al mes",y ="Precio dispuesto a pagar",color ="Preferencia de consumo")# Dividir datos en conjunto de entrenamiento y prueba (80/20)trainIndex <-createDataPartition(nueva_muestra$precio_dispuesto_pagar, p = .8, list =FALSE, times =1)datos_entrenamiento <- nueva_muestra[trainIndex, ]datos_prueba <- nueva_muestra[-trainIndex, ]# Entrenar el modelo de regresión linealmodelo <-train( precio_dispuesto_pagar ~ tazas_mensuales + preferencia_consumo,data = datos_entrenamiento,method ="lm")# Resumen del modelosummary(modelo)# Realizar predicción en el conjunto de pruebapredicciones <-predict(modelo, datos_prueba)# Visualizar relación de tazas_mensuales y precio_dispuesto_pagar con preferencia_consumog1<-ggplot(datos_prueba, aes(x = tazas_mensuales, y = precio_dispuesto_pagar)) +geom_point(aes(color=preferencia_consumo),size=3) +geom_smooth(method ="lm") +labs(title ="Relación entre Consumo y Precio Dispuesto a Pagar por Café",x ="Tazas al Mes",y ="Precio Dispuesto a Pagar",color ="Preferencia de Consumo") +theme_minimal()plotly::ggplotly(g1)# Distribución de las prediccionesggplot(data.frame(predicciones), aes(x = predicciones)) +geom_histogram(aes(y = ..density..), bins =20, fill ="skyblue", color ="black") +geom_density(color ="blue", size =1) +geom_vline(aes(xintercept =mean(predicciones)), color ="red", linetype ="dashed", size =1) +labs(title ="Distribución de la Predicción de Disposición a Pagar por Café",x ="Predicción de Disposición a Pagar",y ="Densidad") +theme_minimal()summary(predicciones)shapiro.test(residuals(modelo))library(lmtest)bptest(modelo$finalModel)# Realizar una predicción para un nuevo datonuevo_dato <-data.frame(tazas_mensuales =20, preferencia_consumo ="Cafetería")prediccion_nuevo <-predict(modelo, nuevo_dato)cat("Predicción del precio dispuesto a pagar para el nuevo dato: ", prediccion_nuevo, "\n")```